MindRouter
Open-Source LLM Inference Load Balancer
Route inference requests across GPU backends with protocol translation, fair-share scheduling, and full observability. Supports OpenAI, Ollama, and Anthropic APIs.
Everything You Need for LLM Inference
MindRouter provides a complete platform for running, managing, and integrating large language models — from a browser-based chat to full OpenAI, Ollama, and Anthropic API compatibility.
OpenAI, Ollama & Anthropic APIs
MindRouter speaks three API protocols natively. Use the OpenAI, Ollama, or Anthropic SDK of your choice — MindRouter translates between them and routes to the best available backend.
- Full
/v1/chat/completionsOpenAI compatibility - Native Ollama API (
/api/chat,/api/generate,/api/tags) - Anthropic Messages API (
/v1/messages) - Streaming, tool calling & structured output across all APIs
- Image, multimodal & embedding support
curl -X POST https://your-server.example.com/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-20b",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in 3 sentences."}
],
"temperature": 0.7,
"max_tokens": 256
}'Works with the OpenAI Python SDK
Change two lines of code — base_url and api_key — and your existing OpenAI Python code works instantly with MindRouter. No new libraries to learn.
- Use
openaiPython package as-is - Async support with
AsyncOpenAI - Streaming with server-sent events
- Compatible with LangChain, LlamaIndex, etc.
from openai import OpenAI
client = OpenAI(
base_url="https://your-server.example.com/v1",
api_key="YOUR_API_KEY",
)
response = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{"role": "user",
"content": "Write a haiku about GPUs."}
],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")Interactive Chat Interface
No setup required — just log in and start chatting. MindRouter includes a full-featured web chat with markdown rendering, code highlighting, file uploads, conversation history, and model switching.
- Real-time streaming responses
- Syntax-highlighted code blocks
- File & image uploads
- Persistent conversation history
- Switch models mid-conversation
- Thinking / reasoning mode
- Web search integration
- Voice input & text-to-speech output
Here's an efficient implementation:
s = [True]*(n+1)
s[:2] = False, False
for i in range(2, int(n**0.5)+1):
if s[i]:
s[i*i::i] = [False]*len(s[i*i::i])
return [i for i, p in enumerate(s) if p]
This runs in O(n log log n) time complexity...
Native Function & Tool Calling
Build AI agents and agentic workflows. MindRouter supports the OpenAI tool calling protocol, enabling models to invoke functions, query databases, call APIs, and orchestrate complex multi-step tasks.
- OpenAI-compatible
toolsparameter - Parallel tool calls supported
- Works with LangChain agents
- Structured JSON Schema outputs
response = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[{"role": "user",
"content": "What's the weather in Moscow, ID?"}],
tools=[{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
}
}
}
}],
)Universal Protocol Translation
MindRouter's innovative translation layer is the engine behind its flexibility. Rather than locking you into a single API format, it translates seamlessly between OpenAI, Ollama, and Anthropic protocols — on both the client and backend sides.
This means any tool, library, or application that speaks one of these protocols can connect to MindRouter — and MindRouter can route to any backend inference engine, regardless of its native API.
- OpenAI-compatible — drop-in for any OpenAI SDK or tool
- Ollama-compatible — works with Ollama clients and libraries
- Anthropic-compatible — supports Claude SDK and tooling
- vLLM & Ollama backends — route to any engine transparently
- Dozens of models — deploy and serve cutting-edge models instantly
Comprehensive Docs & Blog
Everything you need to get started and go deep. The documentation covers API endpoints, authentication, model capabilities, rate limits, and integration guides. The blog features updates, tutorials, and best practices.
Your AI. Your Hardware. Your Control.
Every model served by MindRouter runs on University-owned and University-managed GPUs. No data leaves institutional infrastructure. No third-party cloud providers process your prompts. No external APIs see your research, coursework, or sensitive data.
This isn't just a cost decision — it's a strategic one. Institutional AI sovereignty means full control over which models are deployed, how they behave, and where data flows.
Full Cluster Observability
Monitor every aspect of your inference cluster in real time — from GPU utilization and power draw to token throughput and per-request audit trails.
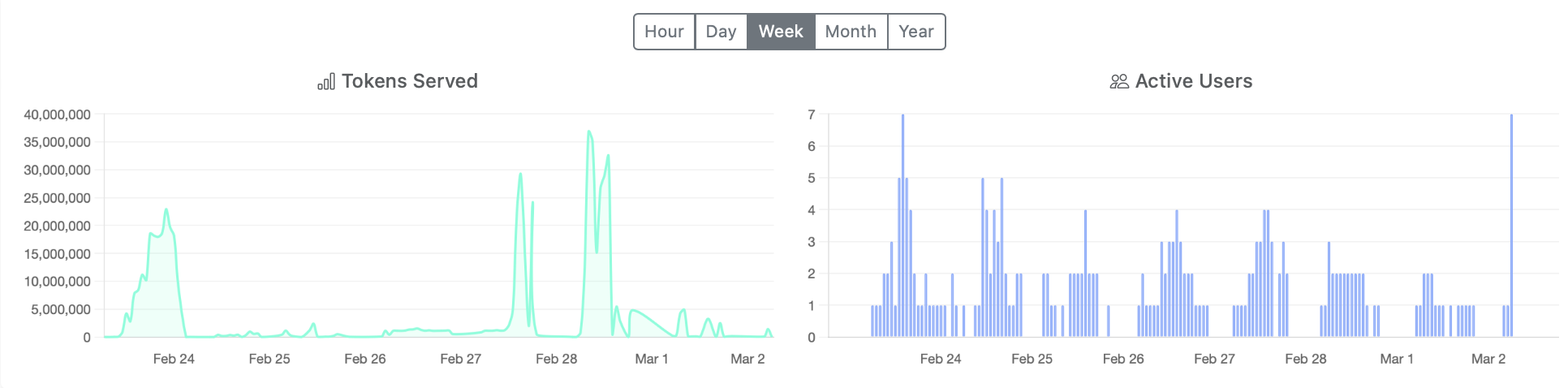
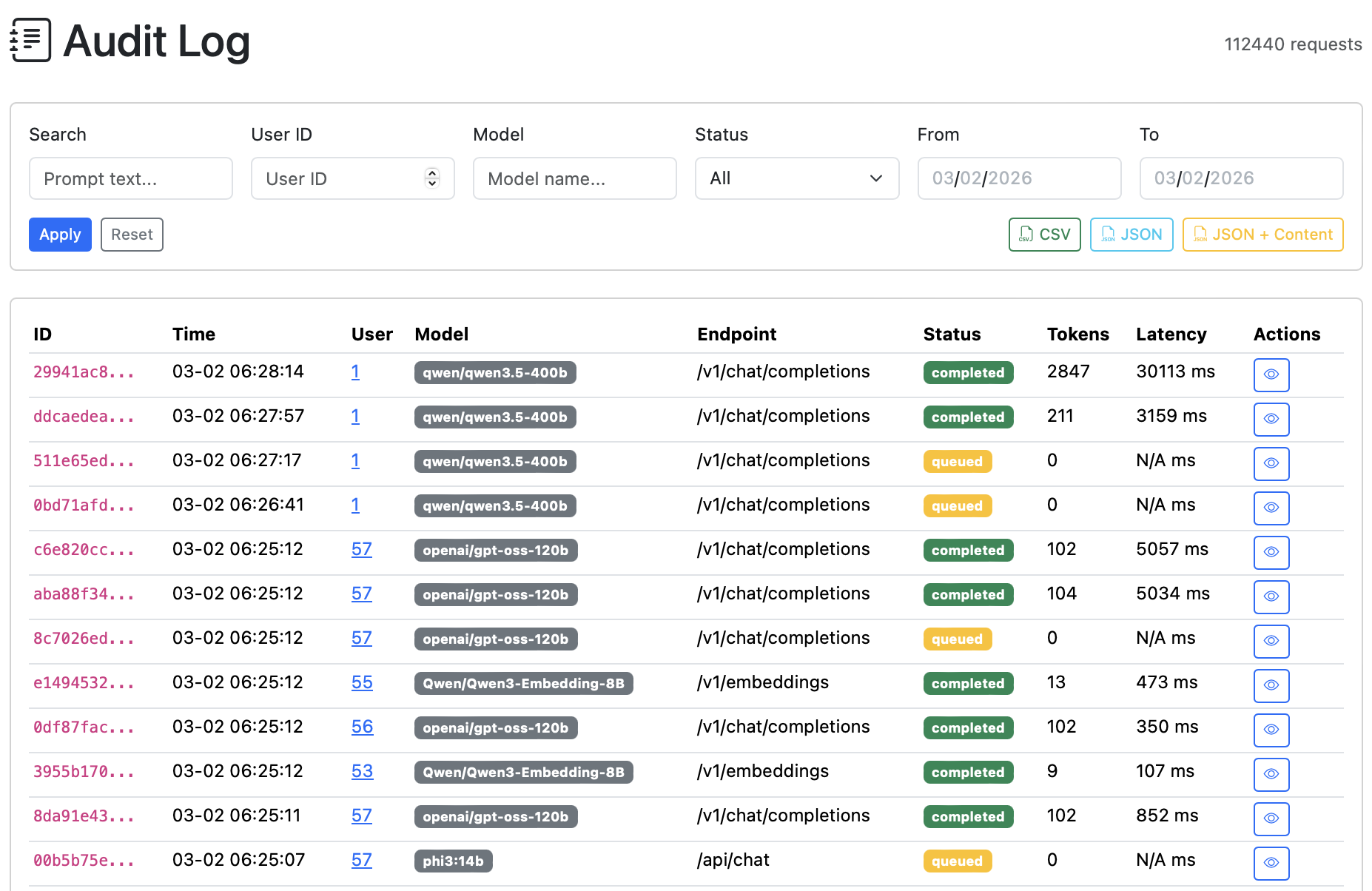
GPU & Inference Metrics
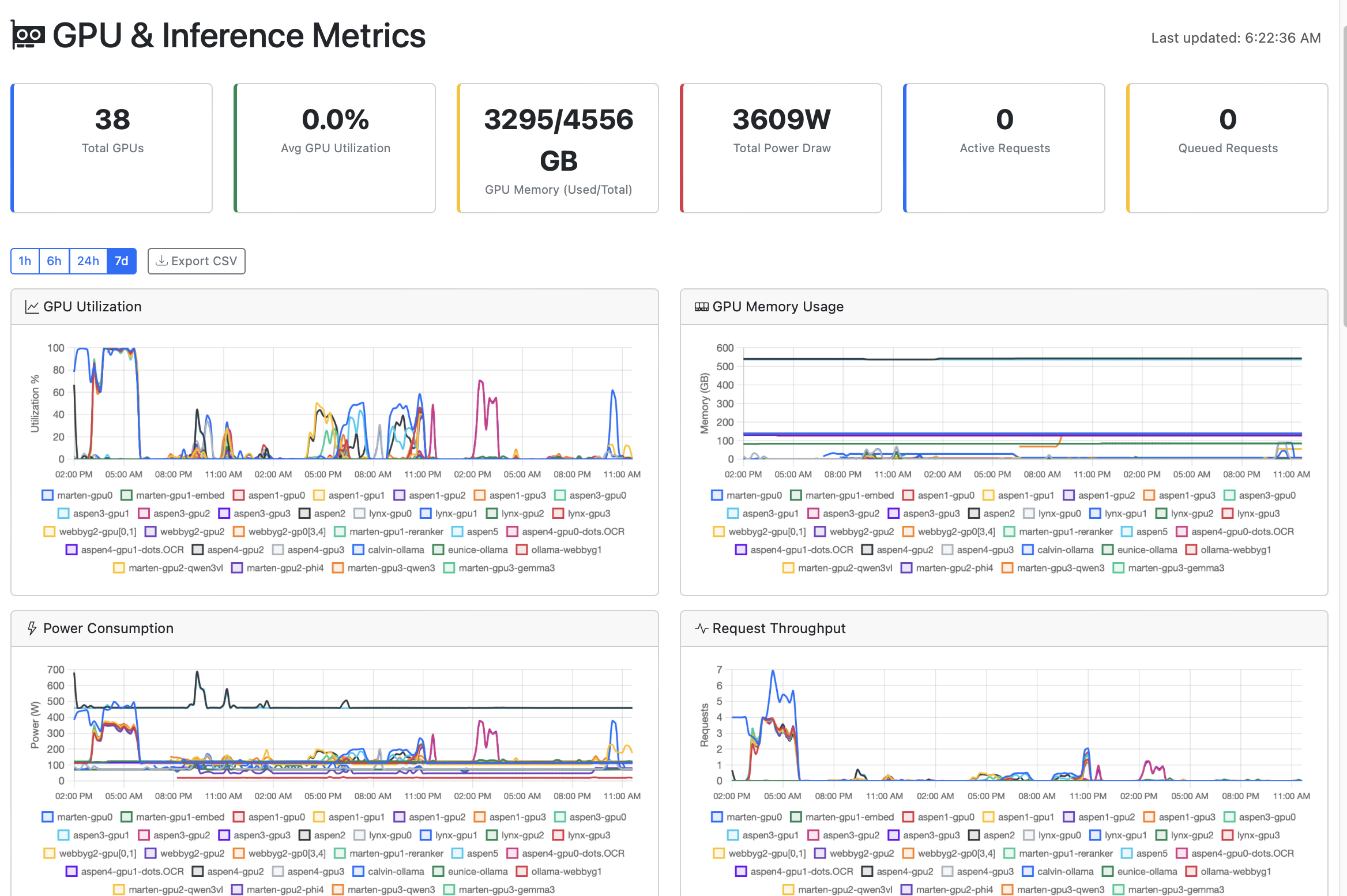
Live Cluster Status
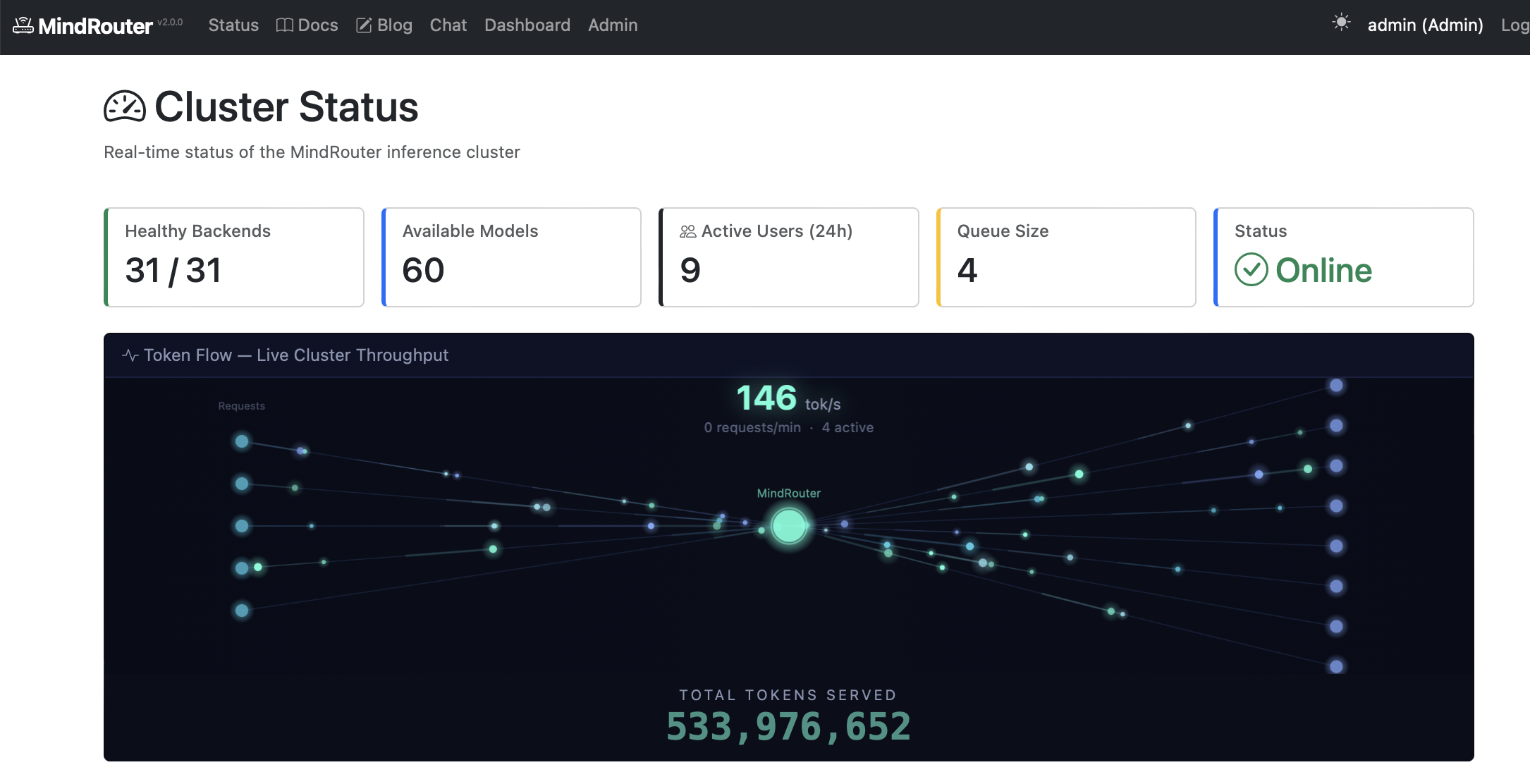
Token & User Trends
Request Audit Log
GPU Telemetry
Utilization, memory, temperature, power draw, and fan speed per GPU with configurable time ranges (1h to 30d)
Live Throughput
Real-time token flow visualization, requests per minute, active request counts, and total tokens served
Audit & Export
Full request audit trail with filtering by user, model, status, and date — exportable as CSV, JSON, or JSON with content
Text-to-Speech & Speech-to-Text
OpenAI-compatible TTS and STT endpoints powered by Kokoro and Whisper, running entirely on local GPU infrastructure. Drop-in replacements for the OpenAI Audio API.
Text-to-Speech
curl -X POST https://mindrouter.example.com/v1/audio/speech \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "kokoro",
"input": "Hello from MindRouter!",
"voice": "af_heart",
"response_format": "mp3",
"speed": 1.0
}' \
-o output.mp3Speech-to-Text
curl -X POST https://mindrouter.example.com/v1/audio/transcriptions \
-H "Authorization: Bearer YOUR_API_KEY" \
-F "file=@recording.mp3" \
-F "model=whisper-large-v3-turbo" \
-F "language=en" \
-F "response_format=json"OpenAI Compatible
Drop-in replacement for the OpenAI Audio API — same endpoints, same request format, works with existing SDKs
Multiple Voices
Kokoro TTS engine with configurable voices, adjustable speed (0.25x–4x), and multiple output formats (mp3, wav, opus, flac)
On-Premise Privacy
Audio processed entirely on institutional GPUs — your voice data never leaves your infrastructure
Built for Production
MindRouter is designed for reliability, observability, and scale — load balancing across GPU backends with intelligent routing and fair-share scheduling.
Load Balancing
Intelligent routing across multiple GPU backends with health checks and failover
Fair-Share Scheduling
Weighted quotas, rate limiting, and fair access across users and groups
GPU Monitoring
Real-time GPU utilization, memory, temperature, and power metrics across the cluster
Protocol Translation
Seamless translation between OpenAI, Ollama, and vLLM API formats
Observability
Prometheus metrics, structured logging, request audit trail, and admin dashboards
Authentication
API key management, Azure AD SSO, group-based access control, and user quotas
Documentation
Comprehensive guides covering API endpoints, authentication, model capabilities, rate limits, Python SDK integration, tool calling, structured output, and more.
View Full DocumentationOpen Source
MindRouter is open-source software released under the Apache 2.0 license. Clone the repo, deploy on your own infrastructure, and contribute back to the project.
$ git clone https://github.com/ui-insight/MindRouter.git
$ cd MindRouter
$ docker compose up -d --build
# MindRouter is now running at http://localhost:8000Get in Touch
Questions about MindRouter? Interested in deploying it at your institution? Drop us a line.